- A
- A
- A
- АБB
- АБB
- АБB
- А
- А
- А
- А
- А
Адрес: 105066, г. Москва,
Старая Басманная ул., д. 21/4
Телефон: +7 (495) 772-95-90 доб. 22734
E-mail: ling@hse.ru



Редакторы сайта — Наталья Борисовна Пименова, Максим Олегович Бажуков, Константин Евгеньевич Сатдаров
Школа лингвистики была образована в декабре 2014 года. Сотрудники школы преподают на образовательных программах по теоретической и компьютерной лингвистике в бакалавриате и магистратуре. Лингвистика, которой занимаются в школе, — это не только знание иностранных языков, но прежде всего наука о языке и о способах его моделирования. Научные группы школы занимаются исследованиями в области типологии, социолингвистики и ареальной лингвистики, корпусной лингвистики и лексикографии, древних языков и истории языка. Кроме того, в школе создаются лингвистические технологии и ресурсы: корпуса, обучающие тренажеры, словари и тезаурусы, технологии для электронного представления текстов культурного наследия.












































Жидкова Е. Г., Занадворова А. В., Какорина Е. В. и др.
Ч. 1: А-И. Вып. 6: дополнительный. Институт русского языка им. В.В. Виноградова РАН, 2026.
Slioussar N., Chernova D., Magomedova V. et al.
The Mental Lexicon. 2026. P. 1-31.
В кн.: Толковый словарь русской разговорной речи. Вып. 6, дополнительный, часть 1: А-И. Ч. 1: А-И. Вып. 6: дополнительный. Институт русского языка им. В.В. Виноградова РАН, 2026. С. 194-285.
arxiv.org. Computer Science. Cornell University, 2024

Вышла новая версия семантического калькулятора RusVectōrēs
В канун праздников мы хотим сделать подарок всем, кто занимается дистрибутивной семантикой, и выпускаем новую версию нашего сервиса - RusVectōrēs 2.0.
Для тех, кто не знал или забыл: RusVectōrēs (http://ling.go.mail.ru/dsm/) вычисляет семантические отношения между словами русского языка c помощью векторных семантических моделей, обученных на больших текстовых корпусах. Что это такое? В дистрибутивной семантике слова обычно представляются в виде векторов в многомерном пространстве их контекстов. Семантическое сходство вычисляется как косинусная близость между векторами двух слов и может принимать значения в промежутке от 0 до 1. Значение 0 означает, что у этих слов нет похожих контекстов и их значения не связаны друг с другом. Значение 1, напротив, свидетельствует о полной идентичности их контекстов и, следовательно, о близком значении. RusVectōrēs позволяет на основе нейронных моделей, обученных нами на НКРЯ, новостном и веб корпусах работать с векторами слов: вычислять ближайших семантических соседей слова, находить коэффициент сходства между парами слов, складывать и вычитать лексические вектора. Модели обучаются при помощи алгоритмов Skip-Gram и CBOW, реализованных в широко известной утилите word2vec.
Мы рассказывали о нашем сервисе на семинаре "Quantitative Approaches to the Russian Language" в Хельсинки в августе и на тьюториале по дистрибутивной семантике на конференции AINL-FRUCT в Санкт-Петербурге в ноябре. С тех пор функционал RusVectōrēs существенно расширился, и теперь у вас есть ещё больше возможностей для исследований. Основные изменения в новой версии таковы:
1) Появился API, так что теперь к сервису можно обращаться автоматически! С помощью API можно для любого слова получить список слов, семантически близких к данному в выбранной модели. Для этого необходимо выполнить GET-запрос по адресу следующего вида: http://ling.go.mail.ru/dsm/MODEL/WORD/api, где MODEL - идентификатор для выбранной модели, а WORD - слово запроса. По запросу отдаётся текстовый файл в формате tab-separated values, в котором перечислены ближайшие десять соседей слова.
2) Создан инструментарий для визуализации данных. Сервис строит карту взаимного расположения слов, которые ввёл пользователь, в выбранной модели, а затем отображает двумерную проекцию этой карты (поскольку изначально мы имеем дело с векторным пространством высокой размерности).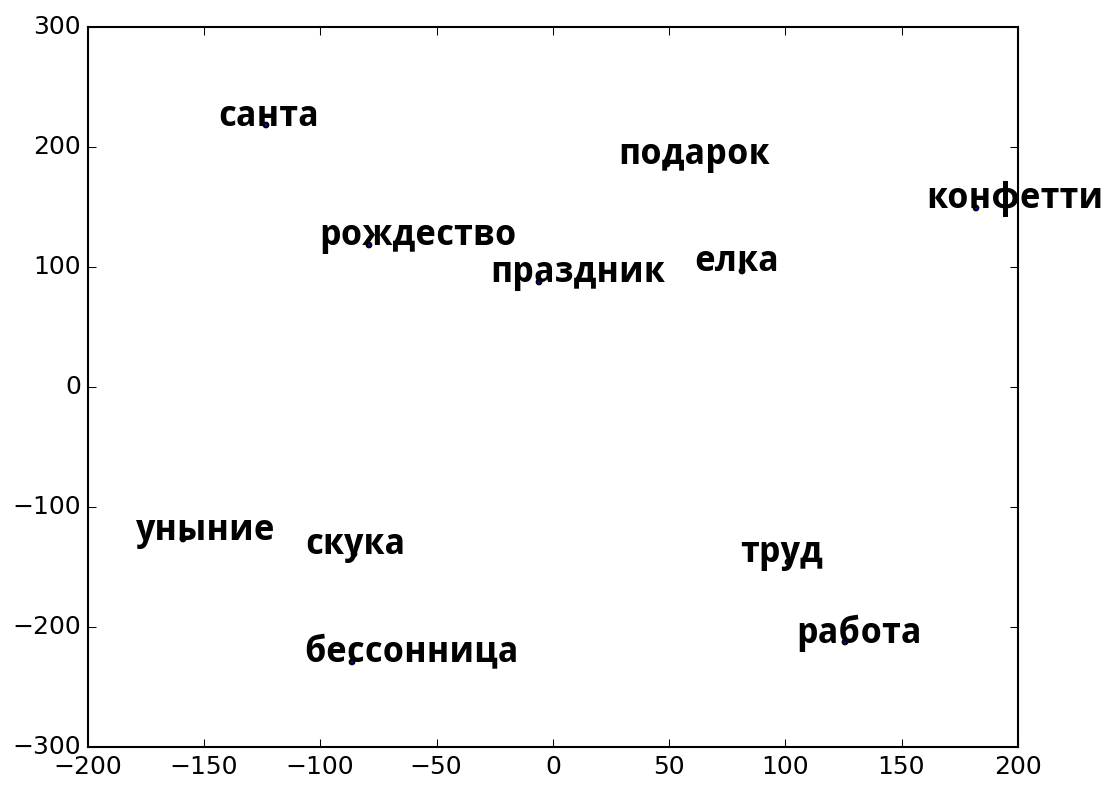
3) Доступна также визуализация вектора для каждого слова в выбранной
модели, которая находится по уникальной для этого слова ссылке.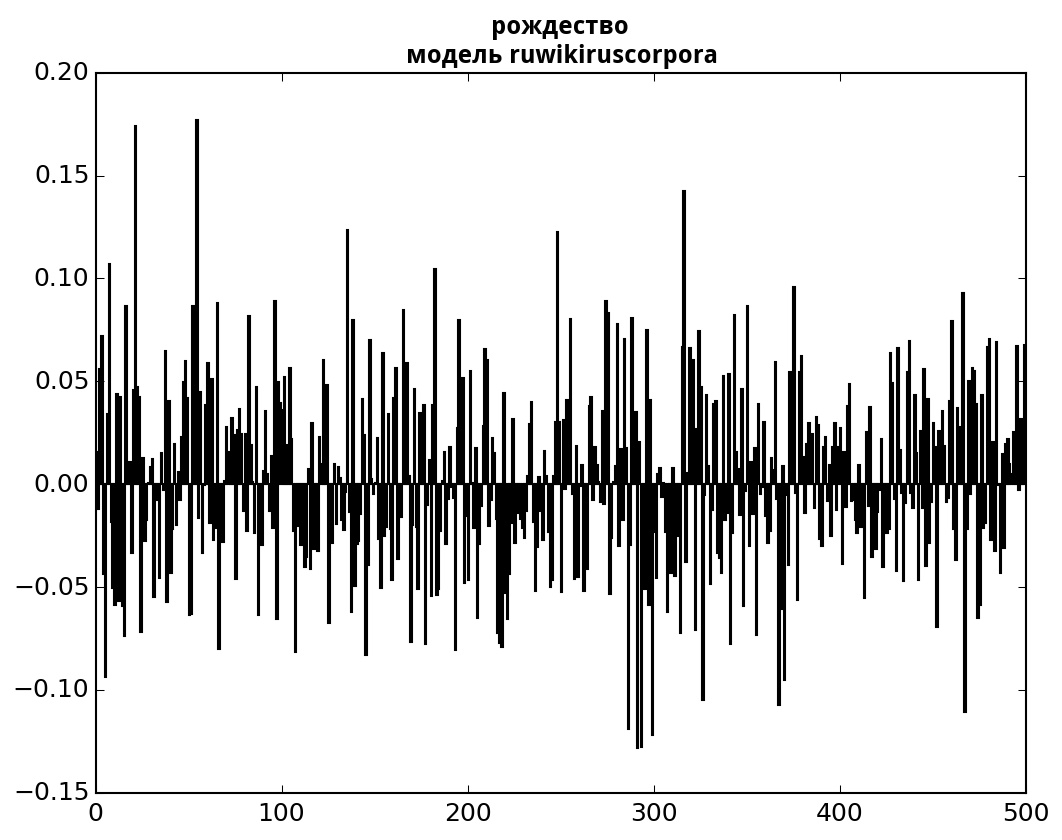
4) Семантический калькулятор теперь может выполнять операции двух видов: решение пропорции вида "найти слово D, связанное со словом C таким же образом, как слово A связано со словом B" (analogical inference) и алгебраические операции над векторами (сложение, вычитание, нахождение центра лексического кластера)
5) Конечно, как и раньше, пользователи могут обучать нейронные модели с заданными параметрами на собственных корпусах, чтобы затем использовать их в работе.
6) Вы всегда можете быть в курсе текущих изменений в работе сервиса, подписавшись на нашу новостную ленту!
Желаем, чтобы для ваших исследований не существовало технических преград! Счастливых праздников!
Команда RusVectōrēs:
Андрей Кутузов (Университет Осло, Высшая школа экономики)
Елизавета Кузьменко (Высшая школа экономики)