- A
- A
- A
- АБB
- АБB
- АБB
- А
- А
- А
- А
- А
Адрес: 105066, г. Москва,
Старая Басманная ул., д. 21/4
Телефон: +7 (495) 772-95-90 доб. 22734
E-mail: ling@hse.ru



Редакторы сайта — Наталья Борисовна Пименова, Максим Олегович Бажуков, Константин Евгеньевич Сатдаров
Школа лингвистики была образована в декабре 2014 года. Сотрудники школы преподают на образовательных программах по теоретической и компьютерной лингвистике в бакалавриате и магистратуре. Лингвистика, которой занимаются в школе, — это не только знание иностранных языков, но прежде всего наука о языке и о способах его моделирования. Научные группы школы занимаются исследованиями в области типологии, социолингвистики и ареальной лингвистики, корпусной лингвистики и лексикографии, древних языков и истории языка. Кроме того, в школе создаются лингвистические технологии и ресурсы: корпуса, обучающие тренажеры, словари и тезаурусы, технологии для электронного представления текстов культурного наследия.












































Жидкова Е. Г., Занадворова А. В., Какорина Е. В. и др.
Ч. 1: А-И. Вып. 6: дополнительный. Институт русского языка им. В.В. Виноградова РАН, 2026.
В печати
Linguistic Approaches to Bilingualism. 2026.
В кн.: Толковый словарь русской разговорной речи. Вып. 6, дополнительный, часть 1: А-И. Ч. 1: А-И. Вып. 6: дополнительный. Институт русского языка им. В.В. Виноградова РАН, 2026. С. 194-285.
arxiv.org. Computer Science. Cornell University, 2024

От автоматической постановки диагнозов до протестов на Болотной
Презентация И.В. Смирнова (PPT, 3.95 Мб)
Первая часть мастер-класса была посвящена интеллектуальному анализу текстов с использованием синтактико-семантического анализа. Стандартный синтаксический анализ позволяет получить лишь формальную структуру связей между элементами предложения, которая напрямую не соотносится с их значением. Так, мы можем говорить о том, что во фразе Мама мыла раму есть некоторая глагольная вершина (мыла), от которой зависят два именных узла - мама и раму, однако для корректного извлечения участников ситуации этого мало. Если же мы добавим в синтаксис семантические роли, т.е. определим, что мама является активным субъектом (агентом, агенсом) действия, а рама - претерпевающим объектом, пациенсом, это уже позволит нам извлекать из текста осмысленную информацию о происходящем событии, производить некоторый логический вывод и т.д.
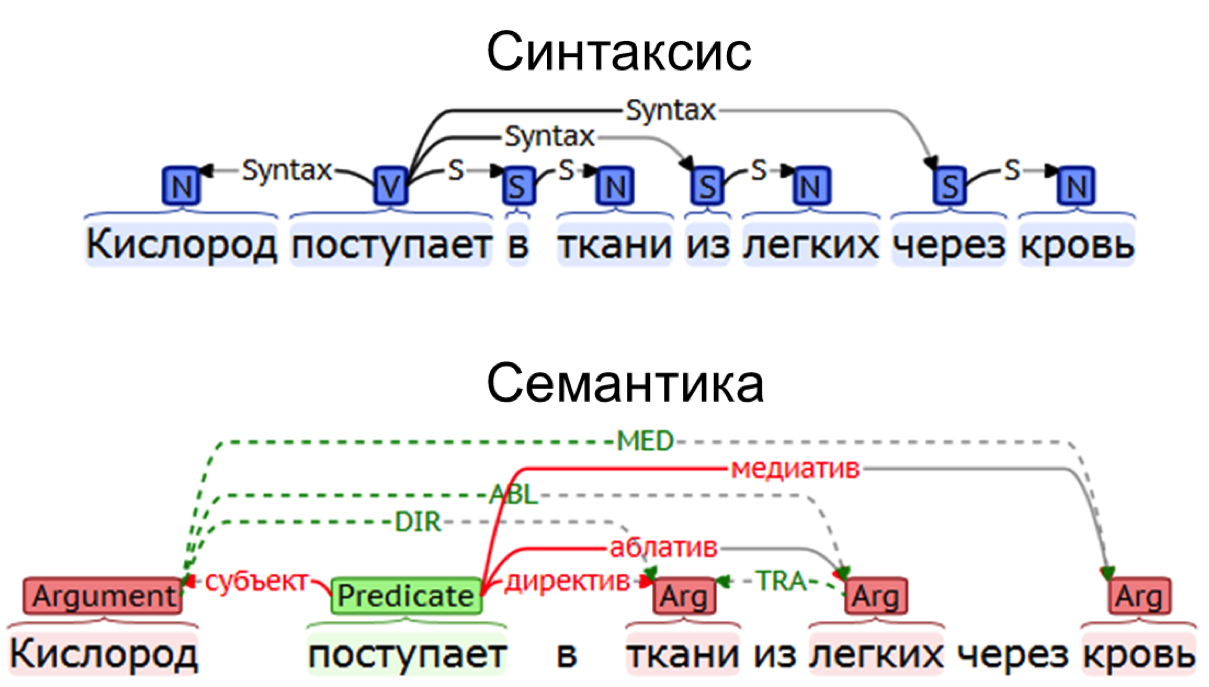
Результаты такого семантико-синтаксического анализа могут быть представлены в виде графа: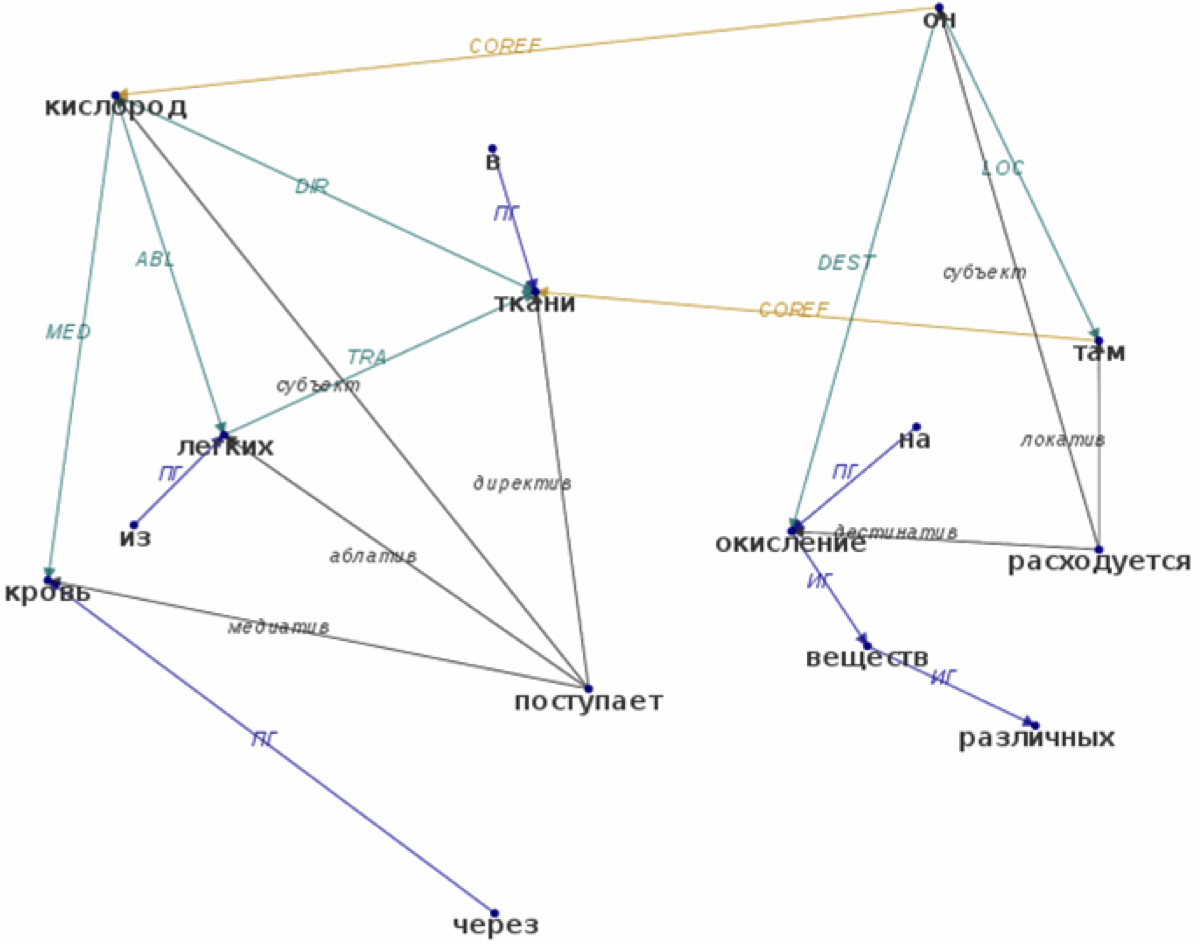
Такое представление текста может быть получено различными способами. В своем выступлении И.В. Смирнов рассказал об опыте применения подходов, основанных на выводе правил из специально составленного семантико-синтаксического словаря, а также на различных способах машинного обучения. При этом он показал, как результаты семантического анализа могут применяться в вопросно-ответных системах для получения ответов на вопросы, заданные на естественном языке.
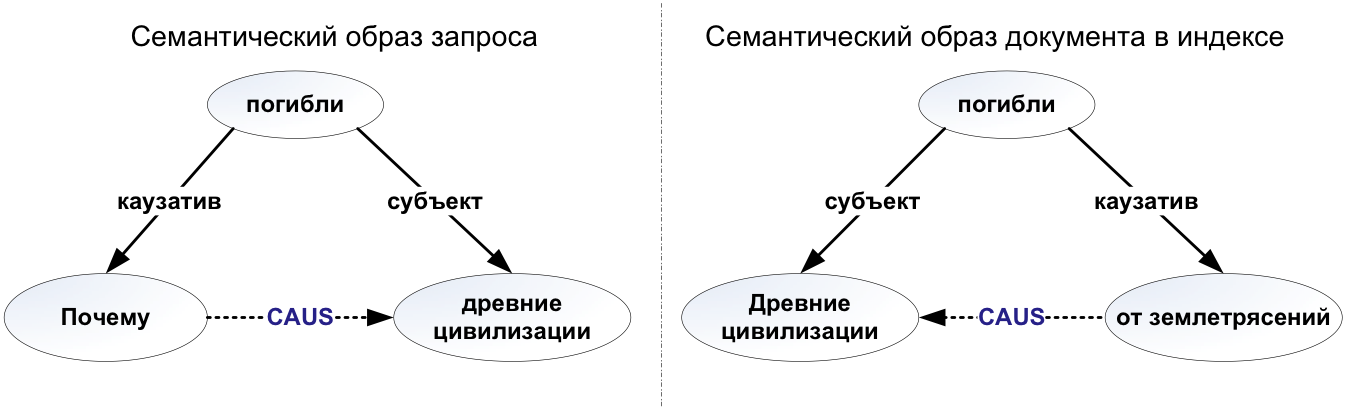
Во второй части мастер-класса речь шла о задачах извлечения информации из научных и медицинских текстах. В первом случае требовалось извлечь из научных статей определения и формулировки научных результатов, выделить в тексте зоны аргументации, соответствующие постановке проблемы, обзору других работ, описанию предложенных в работе методов, результатов экспериментов, а также оценить грамотность текста, уровень использования в нем научной и псевдонаучной лексики. На основании этого предполагается автоматизированное формальное оценивание общего качества научного текста.
Во втором случае необходимо было анализировать клинические записи,, содержащие как числовую (возраст, пол, результаты анализов), так и текстовую (анамнезы, осмотры, эпикризы) информацию. Задача заклчалась в создании системы, позволяющей автоматически диагностировать хронические заболевания, выявлять наиболее значимые признаки и симптомы, а также устанавливать неочевидные, скрытые зависимости в клинических данных. Результаты показали, что анализ текстовых данных дает очень серьезный прирост в качестве диагностики по сравнению с использованием исключительно числовых параметров
Последний сюжет, о котором шла речь на мастер-классе, касался такой горячей темы, как анализ социальных сетей и мониторинг настроений. Система, о которой рассказывал докладчик, измеряла уровень напряженности в сетевых сообществах, опираясь на психолингвистические лексические и семантические признаки. При этом сообщества были изначально разделены на напряженные (политические, в т.ч. националистические) и относительно нейтральные (обсуждение детей, домашних животных, автомобилей). Полученные результаты показали, в частности, что политические протесты зимы 2011-2012 гг. характериовались в первую очередь повышением напряженности в нейтральных сообществах, в остальное время достаточно спокойных и аполитичных.
