- A
- A
- A
- АБB
- АБB
- АБB
- А
- А
- А
- А
- А
Адрес: 105066, г. Москва,
Старая Басманная ул., д. 21/4
Телефон: +7 (495) 772-95-90 доб. 22734
E-mail: ling@hse.ru




Редакторы сайта — Наталья Борисовна Пименова, Максим Олегович Бажуков, Константин Евгеньевич Сатдаров
Школа лингвистики была образована в декабре 2014 года. Сотрудники школы преподают на образовательных программах по теоретической и компьютерной лингвистике в бакалавриате и магистратуре. Лингвистика, которой занимаются в школе, — это не только знание иностранных языков, но прежде всего наука о языке и о способах его моделирования. Научные группы школы занимаются исследованиями в области типологии, социолингвистики и ареальной лингвистики, корпусной лингвистики и лексикографии, древних языков и истории языка. Кроме того, в школе создаются лингвистические технологии и ресурсы: корпуса, обучающие тренажеры, словари и тезаурусы, технологии для электронного представления текстов культурного наследия.












































Жидкова Е. Г., Занадворова А. В., Какорина Е. В. и др.
Ч. 1: А-И. Вып. 6: дополнительный. Институт русского языка им. В.В. Виноградова РАН, 2026.
Родной язык: лингвистический журнал. 2026. № 1. С. 9-58.
В печати
In bk.: Theoretical Issues in the Languages of the Caucasus. Amsterdam: John Benjamins, 2026. Ch. 7. P. 212-236.
В печати
arxiv.org. Computer Science. Cornell University, 2026
Treebank

Разметка высокого качества для корпуса может быть получена несколькими способами - ручной разметкой всего корпуса, разметкой корпуса машиннообученным парсером (который в свою очередь также обучался на корпусе с качественной разметкой), либо разметкой корпуса правиловым парсером. Все три способа являются достаточно трудозатратными, как как на том или ином этапе требуют вовлечения большого количества экспертов.
Проект “Treebank” - это проект по созданию универсального алгоритма автоматического поиска и исправления ошибок синтаксического парсинга, выполненного в рамках грамматики зависимостей. Алгоритм способен обрабатывать разметку любого парсера, работающего с грамматикой зависимостей. Материалом для исследования является синтаксический корпус RusTreebank, размеченный синтаксическим анализатором SyntAutom.
Мы используем небольшой Золотой стандарт этого корпуса и параллельную ему разметку парсера для извлечения выведенных нами на основании анализа ошибок разметки признаков зависимостной связи и обучения на них модели парсера, которая ищет неверную разметку в остальном корпусе. На данный момент алгоритм работает с 0.87 точности и 0.81 полноты для обнаружения ошибок разметки.
Обучая модель, мы всегда проверяли, что признаки, которые использует алгоритм машинного обучения, релевантны и с лингвистической точки зрения:

На графике в числе наиболее значимых признаков, использованных классификатором - длина предложения и расстояние от главного слова до зависимого (1-2, 4 признаки), что соответствует данным, которые можно получить, анализируя наиболее частые случаи ошибок синтаксических парсеров.
Мы также проверяли, какая комбинация и какое количество признаков дает наилучшие результаты: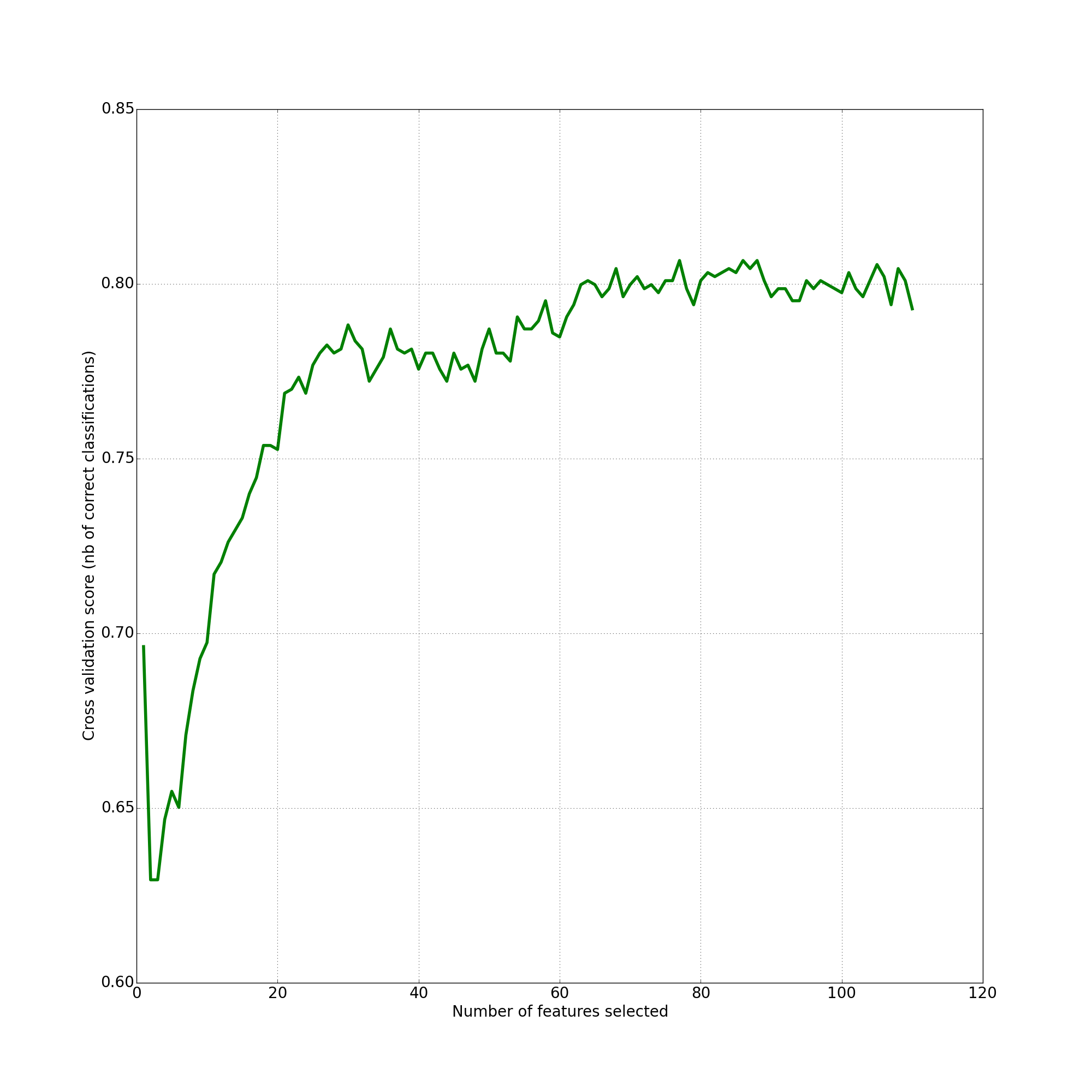

На графиках отображено изменение полноты и точности обнаружения ошибок разметки в зависимости от количества использованных для классификации признаков. Как видно, чем большим количеством признаков описаны объекты выборки, тем выше и точность, и полнота классификации.

Исходный код проекта, реализованный на Python с использованием библиотеки Scikit-learn, находится в открытом доступе и свободен для скачивания (https://github.com/hmyr/Treebank).
Научным руководителем проекта является С.Ю.Толдова